Implementing the DORA metrics


- Audience: IT managers / Lead Developers
Measuring software development performance is a challenge. Traditional metrics often miss the mark. Enter the DORA metrics. These indicators, developed by the DevOps Research and Assessment (DORA) group, offer a powerful way to assess and boost your team's efficiency and effectiveness. In this article, we'll uncover how DORA metrics can revolutionize your software development process.
To enhance your DevOps practices, start by asking yourself these key questions:
- On average, how much time passes between a release being ready and its deployment in production? Do you measure this is minutes, hours, days?
- What defines a release for you? Is it based on a timeframe like a sprint or a day? Is it a git merge from a staging branch, a single feature branch, or perhaps even a single git commit?
- In how many of your deployed releases an issue is found? What is the percentage of this across all deployed releases?
- On average, how long does it take to resolve an issue once it's found?
- If fixing the issue takes significantly less time than the duration identified in question 1, why is that? This is probably called a "hotfix" and introduces (unnecessary) high risk.
Be honest to yourself with your answers and aim to optimize these metrics. By doing so, you'll naturally take the right steps towards building better software.
Software development is art
Developing software requires creativity, mostly in the form of semantics. Of course a developer needs to be able to understand—at least one—programming language syntactically, but that is like knowing how to hold a brush. The real art is in the semantics of what you (need to) write.
Brilliant art can be made in five minutes (or less), while terrible art may take months to create. The same applies to software development. This is why measuring development time is irrelevant to performance—and quality—measurement; it may take a developer a full day to produce one brilliant line of code, but it may also take the same developer five minutes. The same developer may also need a full day to write hundreds lines of code that in the end seem not so good, or they are perfect, it just depends..
But what are relevant things that we can measure? This is the million-dollar question. In the past several—if not many—software development methodologies are proposed to give insights in a software development team. They all have their pros and cons. There is no golden hammer.
Most software development methodologies focus on exactly the development of software. This sounds logical and it does give interesting insights. However, while it does give insights into the performance of a specific team over particular period of time, or for a specific task or set of tasks, it doesn’t help with predicting the future since there are always different constraints. And let’s not forget side-effects like new people joining or old ones leave.
Welcome DevOps
Traditionally, development (Dev) and IT operations (Ops) are separate fields. Engineers in either field are stereotypically different and usually don’t go that well together. The former are—as mentioned earlier—more artists while the latter are usually more strict/rigid, like engineers. Artists need creative freedom and good ones can comprehend lots of chaos at the same time. Stereotypical operations engineers don’t like chaos, they need clear requirements/guidelines to work on.
Operations engineers do like complicated tasks; the more complicated the better. They can be very proud when finishing a very complicated task. For most people, the results are so difficult that they are unable to understand and thus value it. The irony is that this is exactly what they like.
In a nutshell, we just described the mapping of an IT department (consisting of developers and operations engineers) onto the Cynefin framework.
The DevOps movement tries to merge the fields of Dev and Ops, but not by putting the people in a single team, or by hiring unicorn engineers that master both fields, but through automation. In essence, by automating the tasks of the operations engineers. By definition, clear tasks with strict requirements can be automated quite well.
IT is about automating business processes. There is a love/hate relationship between business departments and IT because on the one hand the most time-consuming parts are automated but on the other hand people’s jobs are changing and/or disappearing. This may (will) lead to cultural shifts and even organizational disorder.
Since IT operations is in the complicated field and the more difficult the tasks the better, operations engineers usually welcome automation in their field as with it, they can work on even more difficult tasks because the “easy” ones are already automated.
This seems to be a happy marriage between Dev and Ops, both find common ground in automating the Ops work, hence DevOps.
In 2014 the DevOps Research & Assessment (DORA) group was founded to provide “an independent view into the practices and capabilities that drive high performance in technology delivery and ultimately organizational outcomes”. Since then, each year the group publishes a report about the state of DevOps.
In 2018 the book Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations was published which literally “accelerated” the popularity of the research findings.
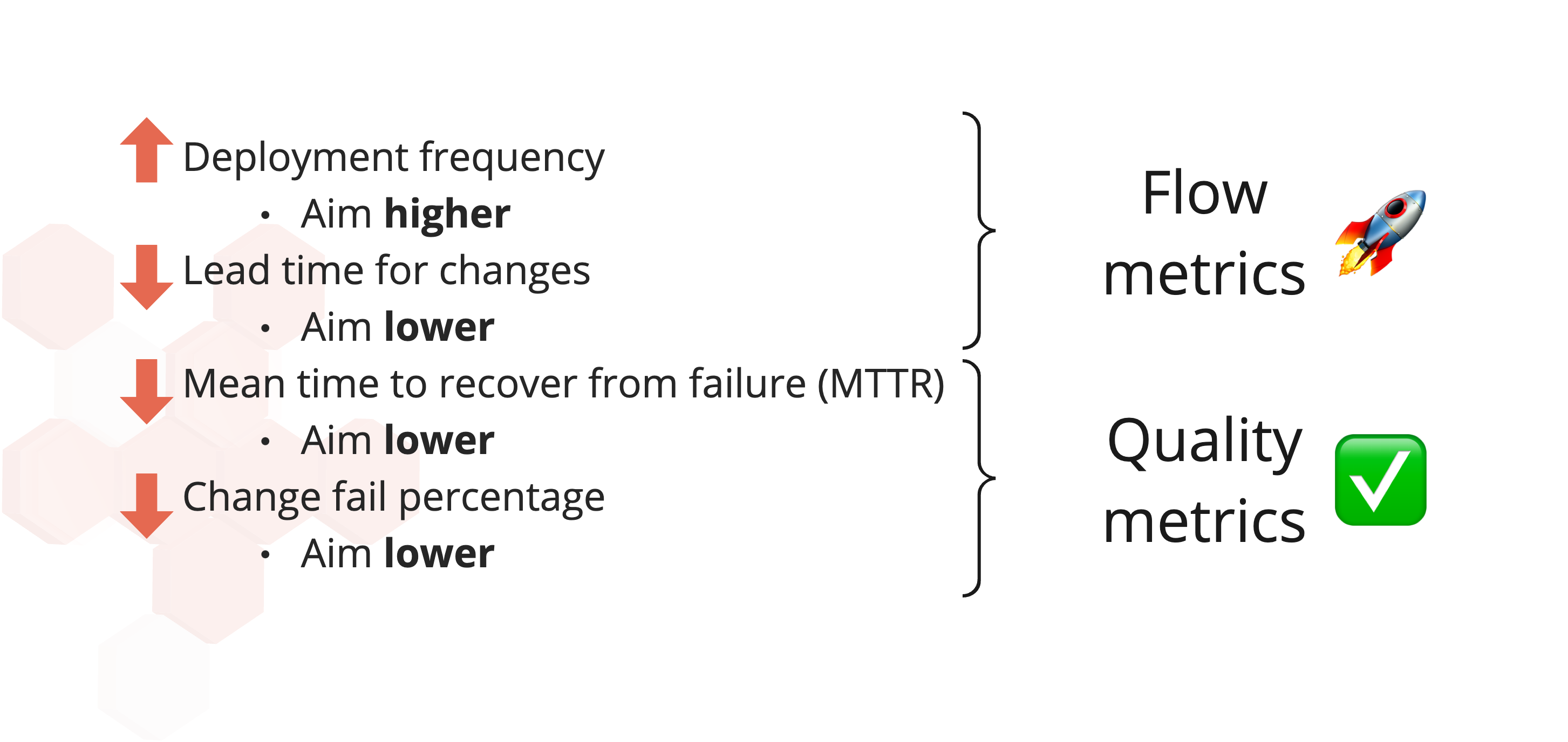
The DORA group defined the so-called DORA metrics. The book Accelerate laid out these metrics in great detail. In short, these are the metrics:
- Deployment frequency
- The frequency of successful deployments in production (per time period).
- Lead time for changes
- The time it takes from the moment coding is done until a successful deployment in production.
- Mean time to recover from failure (MTTR)
- The mean time it takes from the moment an error occurs, to resolving the issue (by a successful deployment).
- Change fail percentage
- The ratio between releases (deployments to production) that need remediation and releases that don’t have issues.
Measuring just these four metrics is enough to get “a useful and quantifiable definition of IT performance in the context of DevOps.”
Now we have a brief understanding of the metrics, let’s talk about how to implement them in practice, what they tell us and how they help—mostly indirectly—to improve performance.
The DORA group mentions the use of version control as an example to improve upon several metrics. In this article, we assume common tooling—such as version control, in the form of git—is already in place. We use them for implementing the metrics.
Git for example, can be used to track time. The moment a developer checks-in code, it marks a timestamp that can be used to measure lead time for changes. Git platforms like Github, Gitlab or Bitbucket provide web-hooks (or similar) to get triggers about code being checked in and other events. These can be used take note.
Taking each individual commit into account is fine-grained, but possible. Taking just pull/merge requests into account is coarse-grained, but equally possible. Commit-timestamps can be manipulated easily by postponing pushing code upstream, this is less likely to happen with pull requests. Though, individual manipulations dilute when more data is collected, by the law of large numbers. Yet, even with manipulations, one cannot trick the metrics and perform window dressing.
The metric is about measuring the time it takes for changes to get live. Some teams put every individual change live, some other teams cluster several changes and put them live together. For the former, just measuring the commit that triggers the deployment to production is enough. For the latter, the time between finishing the work of the first change and the commit that triggers the deployment will be significant for the metric, so needs to be taken into account.
Measuring deployment frequency can be done in several different ways and each way is highly dependant on the way deployments are being performed. Manually marking a deployment as finished successfully is one way to implement. This is probably the best way when deployments also are being performed manually. Even in 2022, this is still a very common way to bring changes to production. Usually clusters of changes are then released, ironically to reduce overhead.
When deployments are (more) automated, an API call or web-hook can suffice to mark a deployment as finished. But the specific implementation of this API call or web-hook depends on the platform that performs the deployment. Jenkins for example may provide a web-hook but Google Cloud Build requires a step to, for example, publish an event to which a DORA measurements aggregation application subscribes to. Or just send an email.
When a deployment is marked finished, this also marks the final timestamp of the lead time for changes metric and thus the calculation can be made.
Having a high deployment frequency (e.g., every day or more) and a low lead time for changes (e.g., one day or less) are the first indications of a high-performing team. It also implies that the team isn’t using a process or methodology that has bi-weekly deliveries because it will “blow up” these metrics immediately.
The nice thing of using the DORA metrics is that when a team is trying to improve upon the figures, they are forced to do this through automation (at some point) and letting go of inefficient delivery processes, like bi-weekly releases. Which has another upside because it reduces risk (more on this later). These changes usually are not limited to the IT team only, it usually affects the business as well as they also need to get used to a new cadence, especially when they are used to do manual testing (eliminating this also reduces risk, ironically).
Just measuring lead time for changes and deployment frequency isn’t enough. While it does indicate performance, it doesn’t indicate quality. The quality metric is in the change fail percentage and the mean time to recover.
You can easily reduce the lead time for changes by just skipping manual user testing and deploy to production immediately. While this is perfectly fine when you are a rockstar developer, most of the time this will result in a high number of bugs and/or production outages. It’s not uncommon for a team to reserve one or more days after a production release for emergency fixes. This is also the main reason why there is this infamous rule in IT: “never deploy on Fridays”.
Each time a release contains a bug or causes an outage, the deployment is flagged as “faulty” and this is the data that is used to cover the change fail percentage metric. This is measuring quality. Together with a high deployment frequency, faulty releases will be diluted in this metric quite fast. Releases that contain lots of features have a high risk of containing one or more bugs. When releasing bi-weekly, releases will not only have a high risk of being faulty, but the metric also stays like that for another two weeks officially. We all know that right after a faulty release one or more emergency releases are done (hotfixes) to stop the bleeding. This may result in even more faulty releases but hopefully the last will be good.
The term “hotfix” was already briefly mentioned above. Hotfixes usually bypass any quality process because it needs to happen fast to get the system operational again. This is where the whole business relies on IT. The moment a hotfix is deployed, the mean time to recover can be calculated.
While the definition of MTTR is quite self-explanatory, the implementation can differ. A timer could start when the last release was deployed and MTTR can be calculated the moment the next release is deployed, assuming this is the hotfix to that issue, but it can also be calculated from the moment someone opens an issue in an issue-tracker and the moment someone signs-off the issue (marks as resolved). The latter is probably the most qualitative implementation. You want to have a low MTTR but ideally not much to recover.
To conclude, to effectively measure the performance of an IT team, the metrics as described above can be used.
The metrics work because they incentivize the team to improve on the right things. As mentioned, improving the deployment frequency cannot go unpunished, as for shortening lead time for changes. The metrics give a natural steer towards less risk and more automation. Having smaller releases already is reducing risk.
With proper automation in place, overhead is reduced to a minimum so there is no need anymore to bundle features into a single release.
Implementing the metric as discussed might be relatively easy, improving upon them might be relatively hard. This is because it involves a few hurdles to overcome for a team and its culture. Changing culture is always hard, not only for IT.
Having any questions after reading this article?
Feel free to reach out, we're happy to help!
Reach out